Why AI Products Fail: They Chase Agency Before Learning ▍
And what to do about it. Learnability is the throttle for agency — and the roadmap starts with tighter loops, not bigger leaps.
The failure pattern no one wants to admit
As AI Agents reshape the future, countless startups will fail along the way. The survivors will master highly learnable use cases, while failed ventures will struggle with agentic systems in domains that resist learnability.
The problem will arise from committing resources and roadmap to dead-end use cases—domains where the system fundamentally can't improve through iteration. This risk can't be overcome by "swapping in" a more advanced model. AI product leaders who assume better models will solve these challenges miss the point entirely: no model upgrade fixes a use case that defies continuous learning.
Looking at Reinforcement Learning for Lessons
Pause for a moment and look back at the principles behind reinforcement learning (RL). In the age of AI product management, RL paints a key lesson we can apply.
Reinforcement learning learns by trial and error—act, observe the outcome, update the policy to maximize long-term reward. AlphaGo worked because it solved credit assignment: tracing future wins back to the moves that caused them. Product teams need the same discipline.
Some moves matter disproportionately; the system must connect them to the eventual win. For an AI system to learn—especially to self-learn—it needs to connect present actions to future rewards. This is the credit assignment problem: How does a system measure the impact of a present action on future outcomes?
Embrace tight loops, avoid loose loops
Think of two possible feedback loops in any AI system: a tight loop (support ticket solved, customer happy; Go move made, eventual win or loss) and a loose loop (marketing email, brand lift in months).
A loop is tight when it has low latency (fast input to outcome signal), high fidelity (trustworthy label), clear attribution (this action caused that outcome), and high iteration volume (dozens per week). Think of Intercom’s Fin AI customer support agent: resolution in minutes, explicit outcomes, auditable logs, and many cases per week.
A loose loop has higher latency, noisier signals, murkier attribution and fewer shots on goal. Think about small business marketing: it could be weeks to months to see impact, the success metrics could be unclear or inaccessible to the product team, and multi-touch causality coupled with low volume can make learning difficult.
For AI product leaders, loose loops frustrate our ability to move up the agentic ladder. If you choose to build a product with a loose loop coupled with an autonomous agent, you may struggle to optimize for outcomes over time. The autonomous marketing agent may send an email that, many months later, contributes to the loss of a client. How will your agent learn from this?
Your feedback loop should be fast, but it also needs to be clear, trustworthy, and frequent. Next, we’ll score loops on these four attributes using the Learnability Gradient.
How To Measure Learnability
Learnability answers a simple question: How quickly and clearly will your system discover the truth about its last decision? Four things decide that:
- Latency — how fast the outcome comes back. Minutes and hours teach; weeks and months blur.
- Fidelity — how trustworthy the outcome is. Ground truth drives progress; vanity metrics game you.
- Attribution — how confidently you link action → result. Causal tests build knowledge; correlations build folklore.
- Iteration volume — how many chances you get. Hundreds of events per week shape behavior; a trickle can’t.
You don’t need a calculator—but a score focuses the debate. If you’re exploring a “slow, fuzzy, uncertain, rare,” slow down and ask yourself: “What one change would make the truth arrive sooner and clearer?” That change – not another prompt, nor a new model – is your next feature.
Learnability Calculator
Credit assignment strength can be measured across four key dimensions. Use this calculator to score your AI use case and understand its learnability ceiling.
AI routes customer support tickets to appropriate agents based on content analysis.
email campaigns
indirect metrics
some confounders
monthly learning
Low Learnability - Start with assist mode, focus on improving feedback loops
The Learnability-First Promotion Model
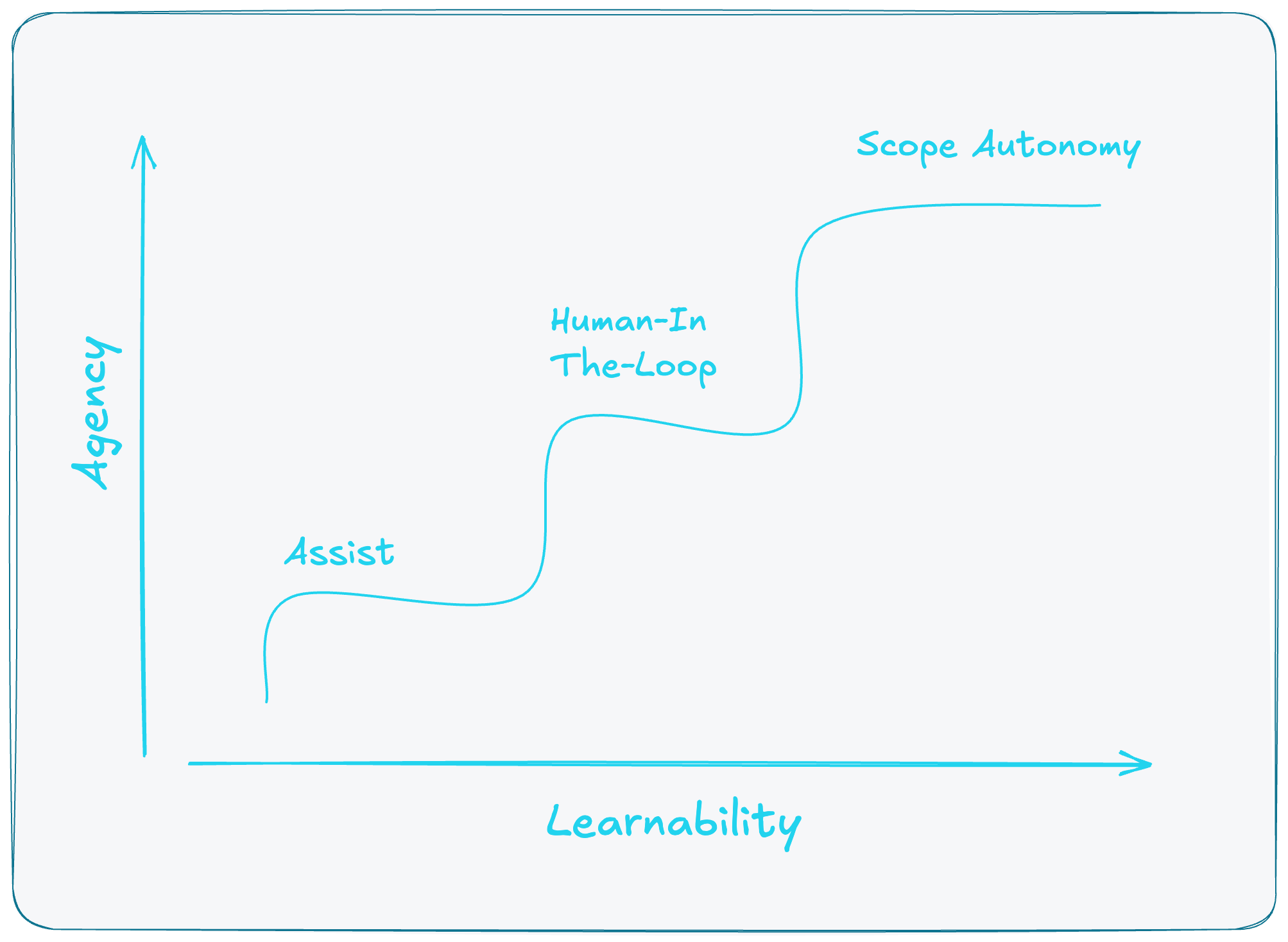
Tighten the loops first. Then, and only then, dial up the agency. Here's how that progression works.
As Reganti & Badam argue, every AI product trades off agency and control; this post operationalizes when to increase agency by measuring learnability.
Smart teams start at Assist. The AI drafts and annotates while a human decides. The output is disconnected—you can't see how it's used or edited. Trust is built through SME reviews: subject matter experts assess quality, spot failure modes, and guide improvements. You iterate on prompts, context, and guidelines until quality is consistently good.
Graduate to Human-In-The-Loop (HITL) when SME reviews show the AI is ready to be wired in. The AI system proposes complete, human approves. Now you can instrument outcomes: measure success rates, track override patterns, and build the feedback loops that enable learning. This is where learnability infrastructure gets built.
Promote to Scoped Autonomy when HITL data shows narrow slices where outcomes are consistently good and overrides are rare. The system acts within boundaries, escalates edge cases, and leaves an audit trail you'd be proud to show a regulator—or a customer.
The teams that win treat autonomy as something you earn, not something you declare.
Here's how that plays out in two very different domains:
What this looks like in practice
Support assistant shows the progression. Start at Assist: the AI drafts replies, but they're disconnected—agents copy, edit, and send manually. You can't see what happens after, so you work with SMEs to review drafts for accuracy and spot failure modes. You iterate on quality—better prompts, more context, clearer guidelines. When quality is consistently good in SME reviews, you promote to HITL: wire the AI into your ticketing system so it proposes complete actions (reply + close ticket), and agents approve with one click. Now you can instrument properly: measure "resolved without reopen," collect explicit thumbs-up/down, track which agents override and why. The latency is minutes, fidelity is high, attribution is clear, and you have volume. After a few weeks of HITL data, you identify narrow slices where outcomes are consistently good and overrides are rare. Promote those slices—password resets, shipping status requests—to Scoped Autonomy with clean escalation paths. Everything else stays HITL.
Verticalized marketing SaaS shows the hard path. A single small business can't learn fast enough—5 deals per month, 6-month sales cycles, impossible attribution. Verticalized SaaS pools learning across hundreds of similar businesses, solving the volume problem. But latency and attribution still suffer. Without this, you can start at HITL — AI proposes campaigns, humans approve — but you'll stay stuck there forever. If you can’t shorten the loop, manufacture one: leading indicators + holdouts.
So you build infrastructure first: track leading indicators that show up fast (meeting booked within 7 days, positive reply within 48 hours), run controlled experiments, and validate monthly that those leading indicators still predict closed deals.
With infrastructure in place, data accumulates. You spot patterns: re-engagement emails to past customers consistently drive meetings that close. Overrides become rare for that slice. You promote it to Scoped Autonomy. Everything else stays HITL. Some slices never tighten enough—and that's honest product design, not failure.
If you want autonomy (you should), earn it
Here’s the quiet craft of AI product leadership:
- Make the truth show up faster. Replace quarterly surveys with real‑time outcomes. Capture “solved w/o reopen,” “meeting happened,” “refund avoided.”
- Make the truth clearer. Swap proxy metrics for ground truth where you can; define rubrics and double‑label a sample to keep humans consistent.
- Make truth causal. Bake in holdouts, temporal switchbacks and a/b tests so you can say this action caused that lift.
- Make truth abundant. Chunk work to create more learning events; mine historical data to pre‑train judgment.
Do these and you’ll feel the system begin to learn. That’s your signal to nudge the agency dial.
Why agentic products really fail
They don’t fail because autonomy is a bad goal. They fail because autonomy shipped into a loose loop can’t learn fast enough to deserve trust. Every miss creates support debt, reputational debt, and roadmap debt. The antidote is boring and beautiful: make the loop tight, then expand what the AI is allowed to do.
Up before right. Ship where truth is close. Earn agency with evidence. If your loop is loose, your agent is guessing.